Contents
Program architecture
The standard program installation includes the following components:
- The Core that includes a graphical interface to monitor and manage the settings of system components.
- One or more Collectors that receive messages from event sources and parse, normalize, and, if required, filter and/or aggregate them.
- A Correlator that analyzes normalized events received from Collectors, performs the necessary actions with active lists, and creates alerts in accordance with the correlation rules.
- The Storage, which contains normalized events and registered incidents.
Events are transmitted between components over optionally encrypted, reliable transport protocols. You can configure load balancing to distribute load between service instances, and it is possible to enable automatic switching to the backup component if the primary one is unavailable. If all components are unavailable, events are saved to the hard disk buffer and sent later. The size of the buffer in the file system for temporary storage of events can be changed.
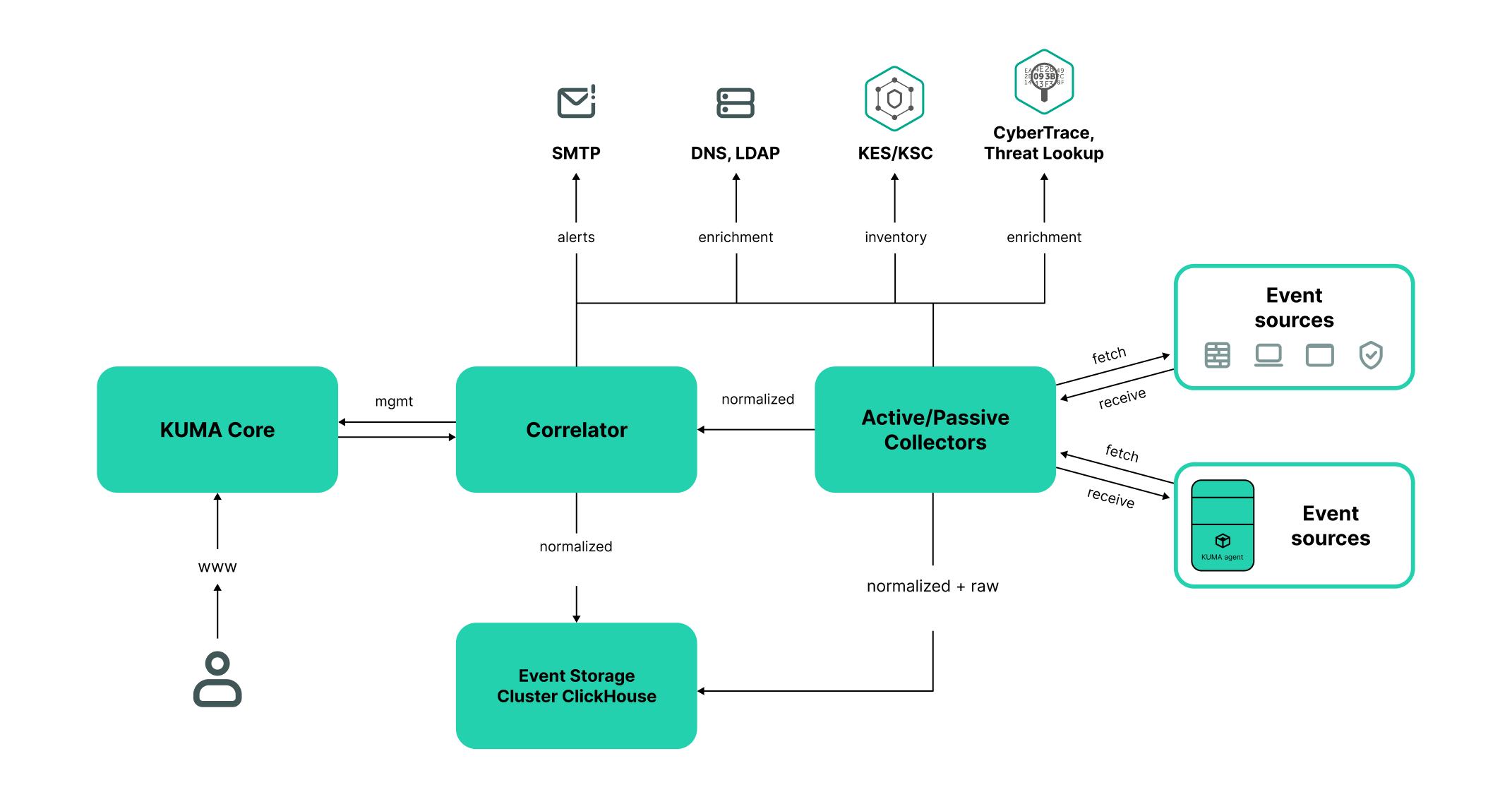
KUMA architecture
Core
The Core is the central component of KUMA that serves as the foundation upon which all other services and components are built. The Core's console provides a graphical user interface that is intended for everyday use by operators/analysts and for configuring the entire system.
The Core allows you to:
- create and configure services, or components, of the program, as well as integrate the necessary software into the system;
- manage program services and user accounts in a centralized way;
- visualize statistical data on the program;
- investigate security threats based on the received events.
Storage
A KUMA storage is used to store normalized events so that they can be quickly and continually accessed from KUMA for the purpose of extracting analytical data. Access speed and continuity are ensured through the use of the ClickHouse technology. This means that a storage is a ClickHouse cluster bound to a KUMA storage service. ClickHouse clusters can be supplemented with cold storage disks.
When choosing a ClickHouse cluster configuration, consider the specific event storage requirements of your organization. For more information, please refer to the ClickHouse documentation.
In repositories, you can create spaces. The spaces enable to create a data structure in the cluster and, for example, store the events of a certain type together.
Page topCollector
A collector is an application component that receives messages from event sources, processes them, and transmits them to a storage, correlator, and/or third-party services to identify alerts.
For each collector, you need to configure one connector and one normalizer. You can also configure an unlimited number of additional Normalizers, Filters, Enrichment rules, and Aggregation rules. To enable the collector to send normalized events to other services, specific destinations must be added. Normally, two destinations are used: the storage and the correlator.
The collector operation algorithm includes the following steps:
- Receiving messages from event sources
To receive messages, you must configure an active or passive connector. The passive connector can only receive messages from the event source, while the active connector can initiate a connection to the event source, such as a database management system.
Connectors can also vary by type. The choice of connector type depends on the transport protocol for transmitting messages. For example, for an event source that transmits messages over TCP, you must install a TCP type connector.
The program has the following connector types available:
- internal
- tcp
- udp
- netflow
- sflow
- nats-jetstream
- kafka
- http
- sql
- file
- diode
- ftp
- nfs
- wmi
- wec
- snmp
- elastic
- etw
- Event parsing and normalization
Events received by the connector are processed using the normalizer and normalization rules set by the user. The choice of normalizer depends on the format of the messages received from the event source. For example, you must select a CEF-type root normalizer for a source that sends events in CEF format.
The following normalizers are available in the program:
- JSON
- CEF
- Regexp
- Syslog (as per RFC3164 and RFC5424)
- CSV
- Key-value
- XML
- NetFlow v5
- NetFlow v9
- IPFIX (v10)
- Filtering of normalized events
You can configure filters that allow you to select the events that meet the specified conditions for further processing.
- Enrichment and conversion of normalized events
Enrichment rules let you to supplement event contents with information from internal and external sources. The program has the following enrichment sources:
- constants
- cybertrace
- dictionaries
- dns
- events
- ldap
- templates
- timezone data
- geographic data
Mutation rules let you convert event field contents in accordance with the defined criteria. The program has the following conversion methods:
- lower—converts all characters to lower case.
- upper—converts all characters to upper case.
- regexp—extracts a substring using RE2 regular expressions.
- substring—gets a substring based on the specified numbers of the start and end positions.
- replace—replaces text with the entered string.
- trim—deletes the specified characters.
- append—adds characters to the end of the field value.
- prepend—adds characters to the beginning of the field value.
- Aggregation of normalized events
You can configure aggregation rules to reduce the number of similar events that are transmitted to the storage and/or the correlator. Configuring aggregation rules lets you combine several events into one event. This helps you reduce the load on the services responsible for further event processing, conserves storage space and the license quota for events per second (EPS). For example, you can aggregate into one event all events involving network connections made using the same protocol (transport and application layers) between two IP addresses and received during a specified time interval.
- Transmission of normalized events
After all the processing stages are completed, the event is sent to configured destinations.
Correlator
The Correlator is a program component that analyzes normalized events. Information from active lists and/or dictionaries can be used in the correlation process.
The data obtained by analysis is used to carry out the following tasks:
- Active lists content management
- Sending correlation events to configured destinations
Event correlation is performed in real time.
The operating principle of the correlator is based on an event signature analysis. This means that every event is processed according to the correlation rules set by the user. When the program detects a sequence of events that satisfies the conditions of the correlation rule, it creates a correlation event and sends it to the Storage. The correlation event can also be sent to the correlator for reanalysis, which allows you to customize the correlation rules so that they are triggered by the results of a previous analysis. Results of one correlation rule can be used by other correlation rules.
You can distribute correlation rules and the active lists they use among correlators, thereby sharing the load between services. In this case, the collectors will send normalized events to all available correlators.
The correlator operation algorithm consists of the following steps:
- Obtaining an event
The correlator receives a normalized event from the collector or from another service.
- Applying correlation rules
You can configure correlation rules so they are triggered based on a single event or a sequence of events. If no alert was detected using the correlation rules, the event processing ends.
- Responding to an alert
You can specify actions that the program must perform when an alert is detected. The following actions are available in the program:
- Event enrichment
- Operations with active lists
- Sending notifications
- Storing correlation event
- Sending a correlation event
When the program detects a sequence of events that satisfies the conditions of the correlation rule, it creates a correlation event and sends it to the storage. Event processing by the correlator is now finished.
About events
Events are information security events registered on the monitored elements of the organization's IT infrastructure. For example, events include login attempts, interactions with a database, and sensor information broadcasts. Each separate event may seem meaningless, but when considered together they form a bigger picture of network activities to help identify security threats. This is the core functionality of KUMA.
KUMA receives events from logs and restructures their information, making the data from different event sources consistent (this process is called normalization). Afterwards, the events are filtered, aggregated, and later sent to the correlator service for analysis and to the Storage for retaining. When KUMA recognizes specific event or a sequences of events, it creates correlation events, that are also analyzed and retained. If an event or sequence of events indicates a potential security threat, KUMA creates an alert. This alert consists of a warning about the threat and all related data that should be investigated by a security officer.
Throughout their life cycle, events undergo conversions and may receive different names. Below is a description of a typical event life cycle:
The first steps are carried out in a collector.
- Raw event. The original message received by KUMA from an event source using a Connector is called a raw event. This is an unprocessed message and it cannot be used yet by KUMA. To fit into the KUMA pipeline, raw events must be normalized into the KUMA data model. That's what the next stage is for.
- Normalized event. A normalizer transforms 'raw' event data in accordance with the KUMA data model. After this conversion, the original message becomes a normalized event and can be used by KUMA for analysis. From here on, only normalized events are used in KUMA. Raw events are no longer used, but they can be kept as a part of normalized events inside the
Rawfield.The program has the following normalizers:
- JSON
- CEF
- Regexp
- Syslog (as per RFC3164 and RFC5424)
- CSV/TSV
- Key-value
- XML
- Netflow v5, v9, IPFIX (v10), sFlow v5
- SQL
At this point normalized events can already be used for analysis.
- Event destination. After the Collector service have processed an event, it is ready to be used by other KUMA services and sent to the KUMA Correlator and/or Storage.
The next steps of the event life cycle are completed in the correlator.
Event types:
- Base event. An event that was normalized.
- Aggregated event. When dealing with a large number of similar events, you can "merge" them into a single event to save processing time and resources. They act as base events, but In addition to all the parameters of the parent events (events that are "merged"), aggregated events have a counter that shows the number of parent events it represents. Aggregated events also store the time when the first and last parent events were received.
- Correlation event. When a sequence of events is detected that satisfies the conditions of a correlation rule, the program creates a correlation event. These events can be filtered, enriched, and aggregated. They can also be sent for storage or looped into the Correlator pipeline.
- Audit event. Audit events are created when certain security-related actions are completed in KUMA. These events are used to ensure system integrity. They are automatically placed in a separate storage space and stored for at least 365 days.
- Monitoring event. These events are used to track changes in the amount of data received by KUMA.
About alerts
In KUMA, an alert is created when a sequence of events is received that triggers a correlation rule. Correlation rules are created by KUMA analysts to check incoming events for possible security threats, so when a correlation rule is triggered, it's a warning there may be some malicious activity happening. Security officers should investigate these alerts and respond if necessary.
KUMA automatically assigns the severity to each alert. This parameter shows how important or numerous the processes are that triggered the correlation rule. Alerts with higher severity should be dealt with first. The severity value is automatically updated when new correlation events are received, but a security officer can also set it manually. In this case, the alert severity is no longer automatically updated.
Alerts have related events linked to them, making alerts enriched with data from these events. KUMA also offers drill down functionality for alert investigations.
You can create incidents based on alerts.
Alert management in KUMA is described in this section.
Page topAbout incidents
If the nature of the data received by KUMA or the generated correlation events and alerts indicate a possible attack or vulnerability, the symptoms of such an event can be combined into an incident. This allows security experts to analyze threat manifestations in a comprehensive manner and facilitates response.
You can assign a category, type, and severity to incidents, and assign incidents to data protection officers for processing.
Incidents can be exported to NCIRCC.
Page topAbout resources
Resources are KUMA components that contain parameters for implementing various functions: for example, establishing a connection with a given web address or converting data according to certain rules. Like parts of an erector set, these components are assembled into resource sets for services that are then used as the basis for creating KUMA services.
Page topAbout services
Services are the main components of KUMA that work with events: receiving, processing, analyzing, and storing them. Each service consists of two parts that work together:
- One part of the service is created inside the KUMA Console based on the set of resources for services.
- The second part of the service is installed in the network infrastructure where the KUMA system is deployed as one of its components. The server part of a service can consist of multiple instances: for example, services of the same agent or storage can be installed on multiple devices at once.
Parts of services are connected to each other via the service ID.
Page topAbout agents
KUMA agents are services that are used to forward raw events from servers and workstations to KUMA destinations.
Types of agents:
- wmi agents are used to receive data from remote Windows devices using Windows Management Instrumentation. They are installed to Windows assets.
- wec agents are used to receive Windows logs from a local device using Windows Event Collector. They are installed to Windows assets.
- tcp agents are used to receive data over the TCP protocol. They are installed to Linux and Windows assets.
- udp agents are used to receive data over the UDP protocol. They are installed to Linux and Windows assets.
- nats agents are used for NATS communications. They are installed to Linux and Windows assets.
- kafka agents are used for Kafka communications. They are installed to Linux and Windows assets.
- http agents are used for communication over the HTTP protocol. They are installed to Linux and Windows assets.
- file agents are used to get data from a file. They are installed to Linux assets.
- ftp agents are used to receive data over the File Transfer Protocol. They are installed to Linux and Windows assets.
- nfs agents are used to receive data over the Network File System protocol. They are installed to Linux and Windows assets.
- snmp agents are used to receive data over the Simple Network Management Protocol. They are installed to Linux and Windows assets.
- diode agents are used together with data diodes to receive events from isolated network segments. They are installed to Linux and Windows assets.
- etw agents are used to receive Event Tracing for Windows data. They are installed to Windows assets.
About Priority
Priority reflects the relative importance of security-sensitive activity detected by a KUMA correlator. It shows the order in which multiple alerts should be processed, and indicates whether senior security officers should be involved.
The Correlator automatically assigns severity to correlation events and alerts based on correlation rule settings. The severity of an alert also depends on the assets related to the processed events because correlation rules take into account the severity of a related asset's category. If the alert or correlation event does not have linked assets with a defined severity or does not have any related assets at all, the severity of this alert or correlation event is equal to the severity of the correlation rule that triggered them. The alert or the correlation event severity is never lower than the severity of the correlation rule that triggered them.
Alert severity can be changed manually. The severity of alerts changed manually is no longer automatically updated by correlation rules.
Possible severity values:
- Low
- Medium
- High
- Critical